Machine Learning Projects
Life Expectancy Prediction
Using Liner Regression
An analysis was performed on the life expectancy from birth of people from countries all over the world.Using liner regression it is possible to make a Prediction to what the life expectancy could look like in the years to come.
With an input of the name of a country and the year you would like to predict, the algorithm will display a graph and asociated prediction.
The data was cleaned and processed with the use of the following technololies:
The data Used on this project was recieved from Our World In Data.
For more information and source code, take a look at my GitHub.

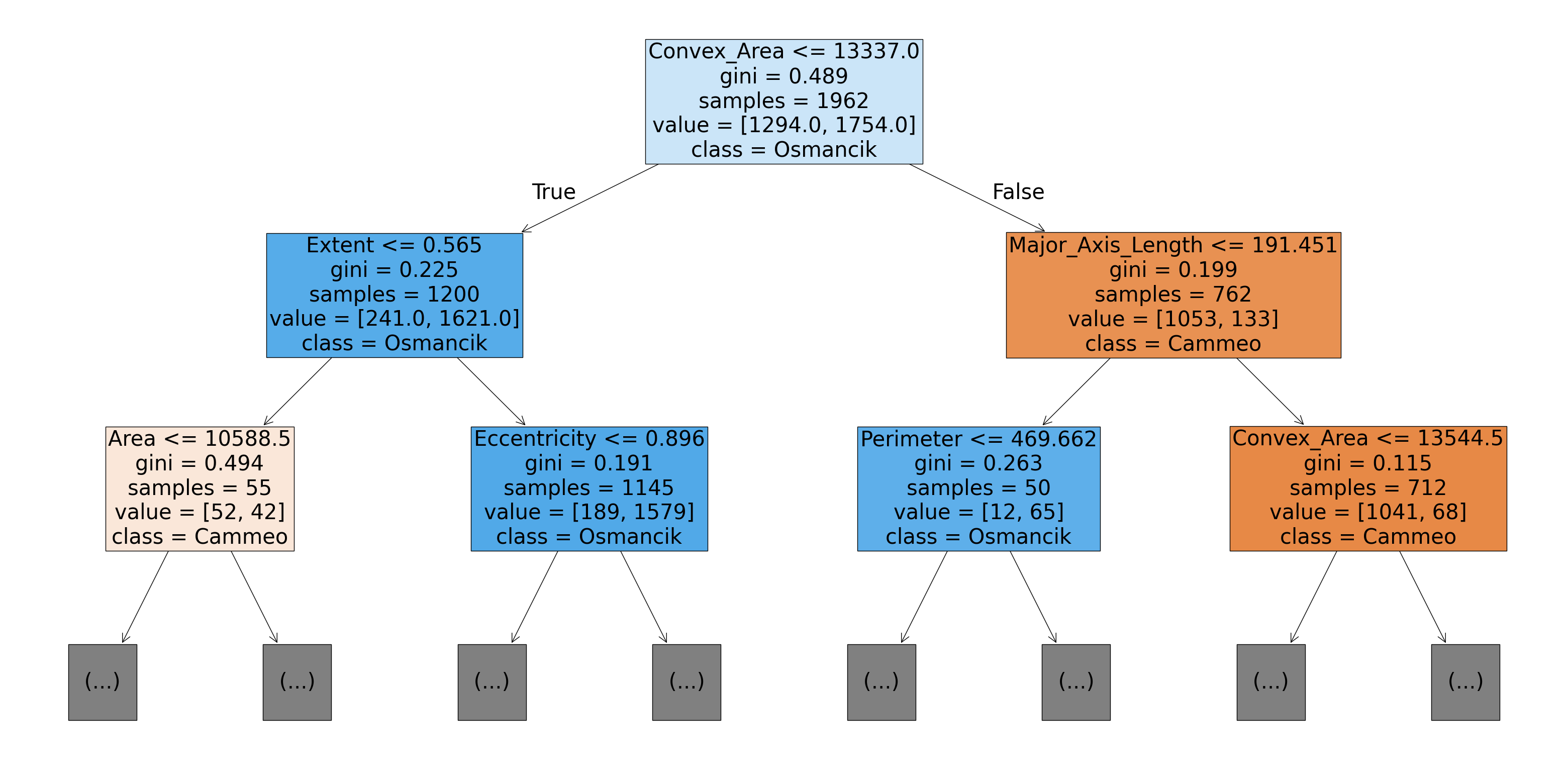
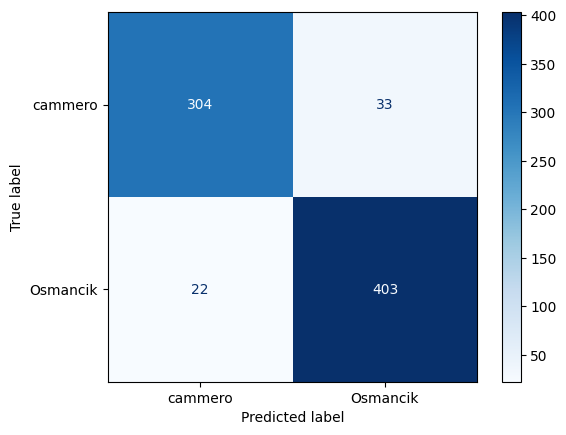
Rice Type Prediction
Using Random Forest
Using a dataset of rice grains in Turkey, and their attributes such as their length, area, etc. The algorithm can predict the difference between the two most common types in Turkey, Cammeno and OsmancikThis is accomplished through the use of the Random Forest machine learning algorithm.
The algorithm, after training, has roughly a 93% accuracy on the remaining test data.
The data is processed with the use of the following technololies:
The data Used on this project was recieved from UC Irvine Machine Learning Repository.
For more information and source code, take a look at my GitHub.
Language Prediction
Using Bayesian Classification
Using a dataset of sentences in different languages, added by users on Tatoeba. The algorithm can predict the difference between the languages English, Spanish and ItalianThis is accomplished through the use of the 'bayesian classification' machine learning algorithm.
The algorithm, after training, has roughly a 99% accuracy on the remaining test data.
The data is processed with the use of the following technololies:
The data Used on this project was recieved from Tatoeba.
For more information and source code, take a look at my GitHub.
Butterfly Type Prediction
Using k-Nearest Neibour
Using a dataset of images of 100 species of butterflys and moths. The algorithm can predict the type of butterfly from an imageThis is accomplished through the use of the k-Nearest Neibour machine learning algorithm.
The algorithm, after training, has roughly a 50% accuracy on the remaining test data.
The data is processed with the use of the following technololies:
The data Used on this project was recieved from Kaggle.
For more information and source code, take a look at my GitHub.
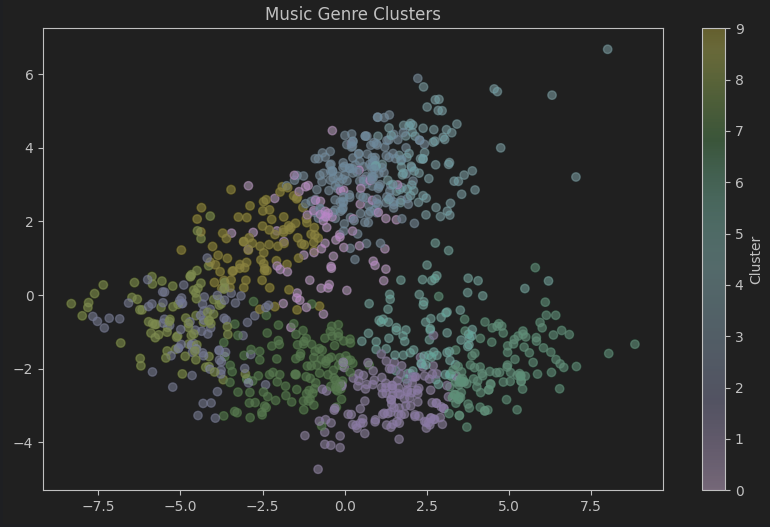
Music Genre Classification
Using k-Means Clustering
Using a dataset of audio files containing music snipits with 10 different genres: blues, classical, country, disco, hiphop, jazz, metal, pop, reggae and rockThis is accomplished through the use of the k-Means Clustering machine learning algorithm.
The processed with the use of the following technololies:
The data Used on this project was recieved from Kaggle.
For more information and source code, take a look at my GitHub.